Publications
* denotes equal contribution.
2025
- Information Fusion
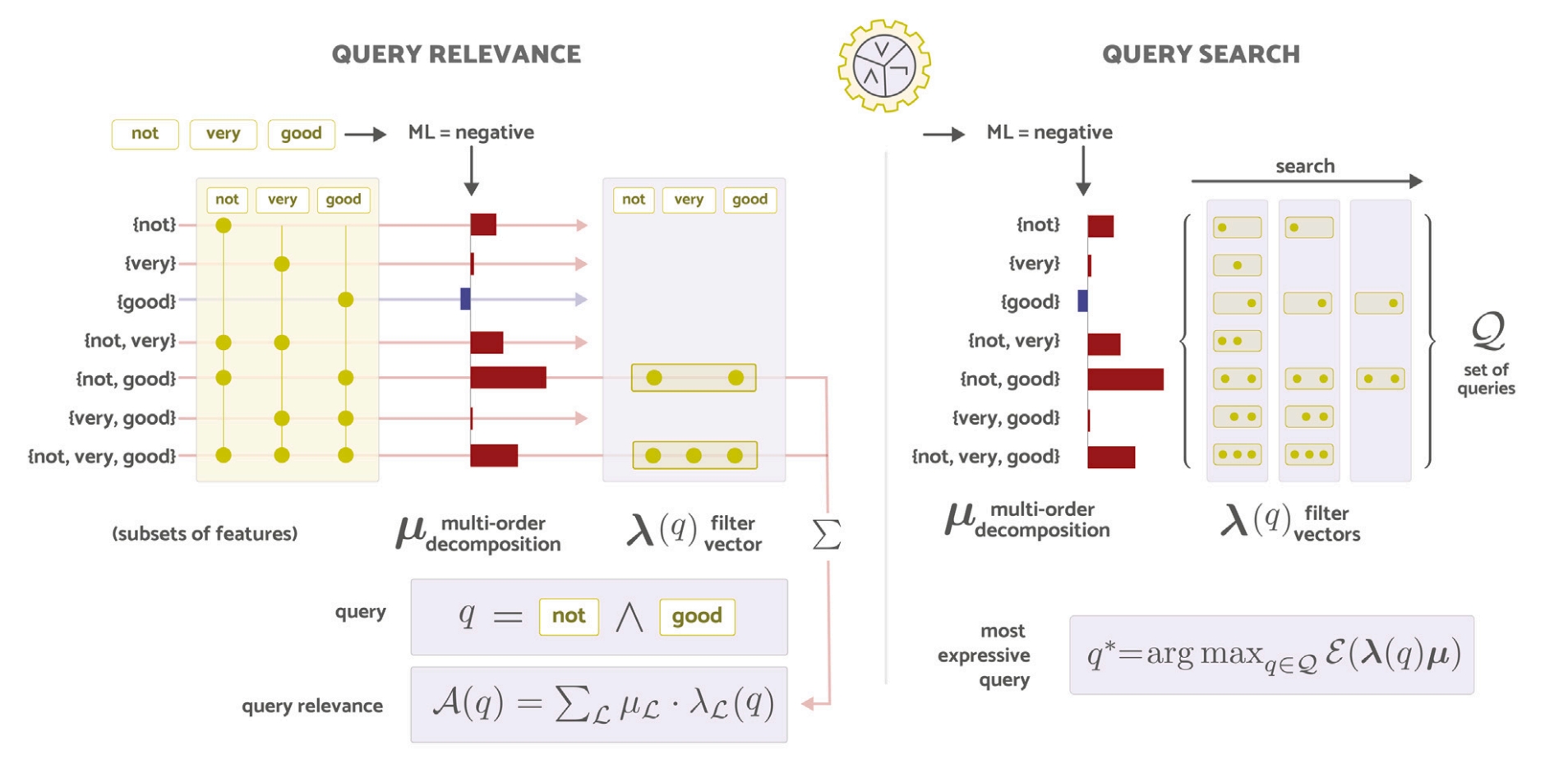
Towards Symbolic XAI – Explanation Through Human Understandable Logical Relationships Between Features
Information Fusion 2025Compositional Reasoning in LLMs & Vision Transformers; Subgraph-Level Model Analysis; Bridging Mechanistic Interpretability with Symbolic Reasoning; Logical Explanations for Transformers & GNNs
2024
- NeurIPS

MambaLRP: Explaining Selective State Space Sequence Models
Conference on Neural Information Processing Systems (NeurIPS) 2024State-Space Models; Mamba LLMs; Vision Mamba; Interpretability; Identifying Model Biases; Analyzing Long-Range Dependencies; Introducing a Novel Evaluation Metric for Needle-in-a-Haystack